论文阅读-26-05w3
新板块,每周论文阅读笔记~
Enhancing Persona Consistency for LLMs’ Role-Playing using Persona-Aware Contrastive Learning
如何让LLM在角色扮演中,长期保持人格一致性
COP(Chain of Persona)
在生成最终的回复之前,先让模型围绕角色人格进行多轮“自我提问-自我回答(self-questioning & self-answering)”。模型会结合角色设定与当前对话上下文,主动思考角色会怎么想、怎么说、是否符合人物性格等问题,形成一系列中间推理过程。
随后,模型再给予这些 persona reasoning 生成最终回复。相比传统直接 role-play 的方式,COP将原本隐式的人格推理过程显式化,从而增强模型在 role-play 过程中的 persona consistency (人格一致性)。
举个栗子
输入:
1 | |
模型不会直接回复。
而是先想:
1 | |
最后再输出:
1 | |

两阶段微调过程
- 利用 GPT 生成带有 self-questioning 过程的 COP 数据,并通过 SFT 的方式,让小模型学习这种“先进行 persona reasoning,再生成回复”的行为模式,提升模型对 persona prompt 的遵循能力
- 模型(当前正在训练的模型自己生成的)分别生成“带 persona”与“不带 persona”的两种回复,并构造 preference pair,通过对比优化使模型更偏向 persona consistency 的输出,进一步增强角色一致性与 role-play 能力
大模型训练过程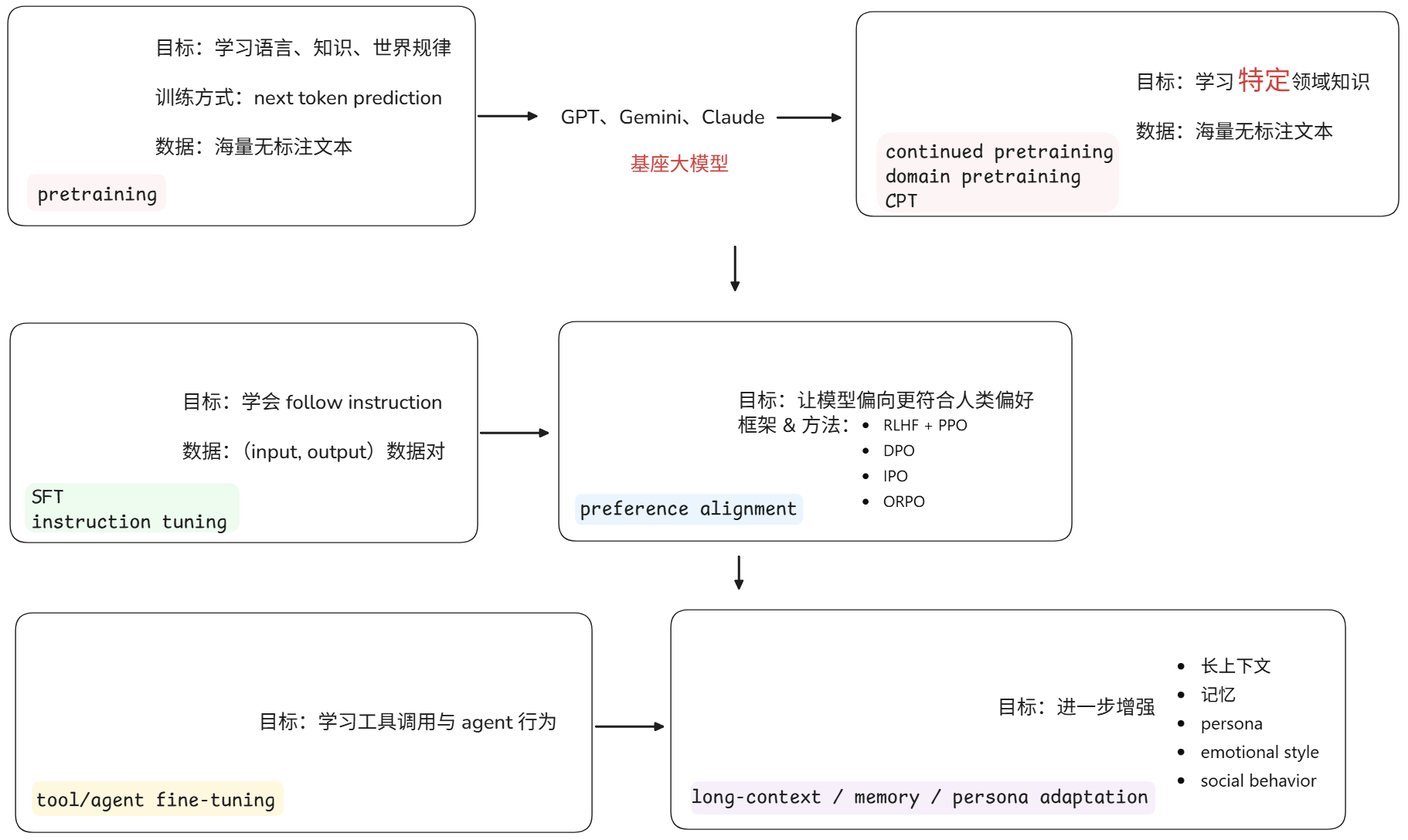
RLHF(Reinforcement Learning from Human Feedback)框架!!!
用人类偏好对齐模型
流程通常为:模型生成多个回答 -> 人工选择更好的 -> 训练reward model -> 强化学习优化模型
举个栗子
例如《爱情公寓》里的曾小贤:
用户说:
1 | |
模型生成:
A:
1 | |
B:
1 | |
人工会觉得:
A 更像曾小贤、更温柔。
于是:
模型学习:
1 | |
PPO(Proximal Policy Optimization)评估优化方法
执行强化学习优化的算法,负责根据 reward model 的分数更新模型参数,增强高分回答的生成概率
巴特PPO存在 复杂 不稳定 吃算力 的问题,需要训练一个 reward model 的 benchmark 用于评估量化结果
DPO(Direct Preference Optimization)评估优化方法
直接学习 preference pair,根据提供的两个例子(一个是更优解,一个是次解,这个是输入的时候就已经确定的,有所标注),让模型更偏向更优解
Teacher-Student Model
一种利用强模型(teacher model)指导弱模型(student model)训练的范式。通常由高能力模型生成高质量数据(如 QA、CoT、persona reasoning 等),再用于训练较小模型学习相同的行为模式
常用于 SFT、模型 distillation、synthetic data generation
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
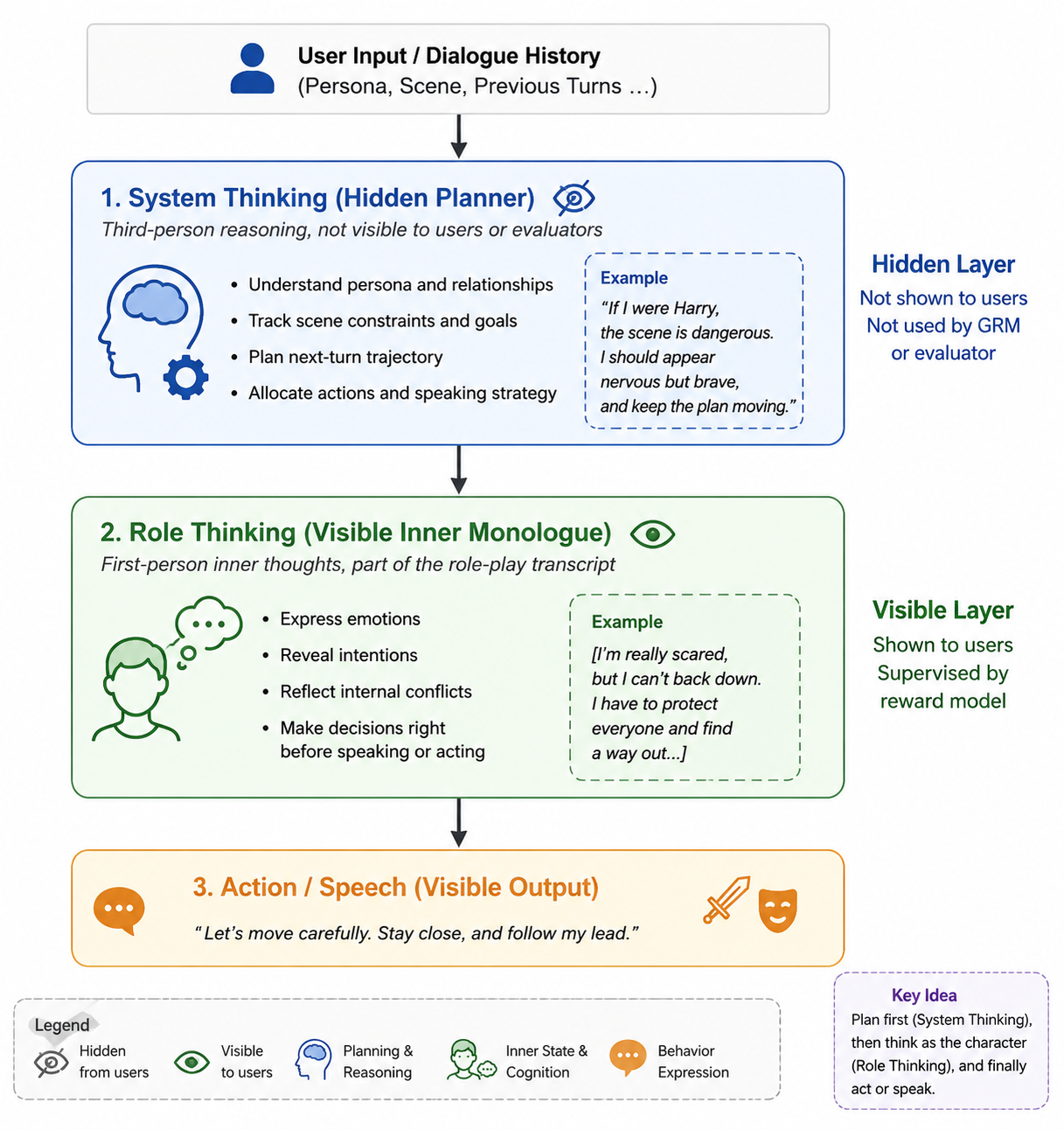
通过双层思维(Dual-layer Thinking)、推理增强数据构建以及基于偏好的 RL,使 LLM 在角色扮演中不仅能够模仿角色的语言风格,还能够模拟角色的内在思维、动机与决策逻辑,实现更一致、更自然的 role-play。
Dual-layer Thinking
把角色扮演中的推理过程拆成了两个不同的层次:
- system thinking
- role thinking
模型在输出前,先要理解角色和场景,再带入情境表达情绪、动机和行动
system thinking
一种第三人称、隐藏式的规划过程。model 在这一阶段理解角色设定、当前场景、对话历史和各种约束,并规划下一轮应该如何行动或回应。
role thinking
角色第一人称的内心活动,作为角色扮演文本的一部分呈现。主要刻画角色在说话或行动前的情绪、意图、动机和决策过程。相比 system thinking,更强调角色本身的主观体验。

Reasoning Data Synthesis
如何构建符合 HER 的推理训练数据。将参考数据优化为包含“规划-内心思考-动作/语言”的推理过程。分为三阶段
Role Thinking Augmentation
根据原始的对话补齐 role thinking,添加 role 的 emotions,intentions,motivations
例如:
原始对话:
1
Harry: Let's go.HER 会自动生成:
1
2[我其实很害怕,但我不能退缩。]
Let's go.System Thinking Construction
生成隐藏式角色规划与场景推理
Integration & Context Augmentation
增强角色背景与场景约束
RL for role-play Generation
从 SFT 环节进入了 RL 部分,对模型进行继续优化。
模型生成新的 role-play response,并与 frozen SFT model 的输出进行对比,再由 GRM(Generative Reward Model)进行 preference judgement,利用 PPO/GRPO 更新 policy,强化更符合角色设定与场景逻辑的行为模式
Preference Distribution
在角色扮演模拟(role-play simulation)中,存在一个根本性的挑战:人类偏好本身并不存在统一、客观且可验证的标准。对于同一角色、同一情境,不同用户往往会产生不同的理解与评价,因此模型很难像数学推理任务一样,依赖唯一正确答案进行优化。然而,模型 training 与 RL 过程又必须依赖某种稳定的优化目标,这使得 Preference Distribution 的评估方式成为一种评估方法,让模型学习多数人能接受的行为模式,而非追求绝对正确的唯一输出。
在 Preference Distribution 作为评估方法的情况下,使用 LLM 作为评估器(LLM-as-a-Judge)的方案成为主流,主要的原因为:
高质量的人类评估成本很高。尤其是在长程、多轮、开放式 role-playing task 中,几乎无法实现大规模持续的标注。
因此,researcher 通常使用能力更强的 LLM 作为近似的人类偏好代理(proxy evaluator),类似 teacher-student model,由更强模型提供符合主流人类偏好的评估信号,再用于优化目标模型的行为分布。虽然这种方法不能解决“偏好主观性”的问题,但是它提供了一种当前阶段较为可以扩展、可以规模化的方案。
传统 SFT 到 COT 的推理训练方法
传统的监督微调(SFT)通常采用 input - output 数据对的格式,让模型学习“面对某种输入时,应该输出怎么样的回答”。这种方式本质上是一种 Imitation Learning(模仿学习),模型重点学习的是语言风格、回答模式以及符合人类偏好的最终输出结果。
像 CoT 这样的推理范式,是在训练数据中间加入显式的推理过程。经典的 CoT 是 “Question - Reasoning - Answer”。HER 这篇论文中采用了“Context - System Thinking - Role Thinking - Speech/Action”的格式。相较于 SFT,这样的推理范式能够让模型模仿者进行思考分析。
Pattern Collapse
指的是模型在训练过程中逐渐收敛到单一、固定的生成结构或表达模式,从而失去交互多样性与灵活性,显得很机械。
避免 Pattern Collapse 的原因:
- LLM 不是传统意义上的程序化状态机,而是在模拟人类在不同情境中的认知和表达。人的思维并不是严格线性的,不会永远遵循固定的流程。人在交流中有时候会先行动再意识到自己的情绪,呈现跳脱、冲动、犹豫的状态
frozen SFT model
在这里,指的是已经经过 SFT 调参过的模型,在 RL 阶段,她会被冻结参数,作为稳定的 baseline/。reference model,与当前正在优化的 model 进行对比,为 Reward Model 提供 Preference Comparison 的参考对象。
PaGER-Sync ADICVIDEO: Player affective gaming experience & responses - synchronized ADICVIDEO dataset
构建了一个 多模态、时间同步 的游戏情绪数据集。研究者让25名大学生分别玩三个游戏:Tetris、Sonic Racing 和 Fall Guys。每个游戏大约20分钟。
测量工具
使用 Empatica E4 手环采集生物信号。皮电活动(Electrodermal Activity,EDA)、血容量脉搏(Blood Volume Pulse,BVP)和皮肤温度(Skin Temperature,TEMP)
使用 FaceReader 软件从视频记录中提取细粒度的面部表情特征描述,其中涵盖了面部动作单元(Facial Action Units,AUs)、效价-唤醒(Valence-Arousal)估计、离散情绪标签
收集参与者的心理量表,包括 游戏成瘾量表(Gaming Addiction Scale)、正负性体验量表(Scale of Positive and Negative Experience)、情绪调节问卷(Emotion Regulation Questionnaire)、参与者的性别