论文阅读-26-06w3
每周论文阅读笔记~
NitroGen: An Open Foundation Model for Generalist Gaming Agents
把互联网上的游戏视频变成可训练的“动画-动作”数据,训练得到一个跨游戏的数据动作模型
related work - gaming agents
相关方法可以分为三个方向
1️⃣ reinforcement learning
相关的例子:DQN、AlphaGo、AlphaStar、OpenAI Five。这一类方法通常依赖人工设计的奖励函数、手工特征,以及专门为某个游戏设计的模拟器。
2️⃣ LLM for high-level reasoning
相关的例子:Voyager、Cradle。这一类方法可以让 LLM 做规划、决策和任务分解,但是依赖手工设计的接口,需要为游戏专门做一套暴露状态、动作、交互方式的接口。
3️⃣behavior cloning
相关的例子:MineRL、VPT、SIMA、CATO、Dreamer 4。直接从像素画面或者游戏状态中学习行为。依赖由人类演示的数据或强化学习生成的数据构建数据集(🌟NitroGen 属于这一种 🌟)
evaluation suite
用 Gymnasium API 包装游戏,统一测试接口,将多个游戏包装在一个标准环境中,让 agent 通过类似强化学习的方式与游戏交互
具体来说,agent 每一步都会:
1 | |
论文中的 30 个任务大致分为三类,主要指标是任务完成率
1️⃣ combat tasks,也就是战斗任务,比如打敌人、boss fight、战斗遭遇等,共 11 个。
2️⃣ navigation tasks,也就是导航任务,比如到达指定地点、穿越区域、在地图中移动探索等,共 10 个。
3️⃣ game-specific tasks,也就是游戏特定任务,比如某些游戏独有的机制、平台跳跃、探索、解谜等,共 9 个。
Game-Theoretic Lens on LLM-based Multi-Agent Systems
用博弈论作为统一框架,理解多模态的智能体系统
Game Theory
博弈论研究的是多个理性决策者之间的策略互动。每个玩家的结果不只取决于自己做什么,也取决于其他玩家做什么。一个博弈论的系统至少需要说明三件事情:谁参与、能做什么、做完以后各自得到什么结果
两类策略
1️⃣ pure strategy。玩家明确选择某一个具体行动。比如 agent A 选择“合作”,agent B 选择“背叛”。
2️⃣ mixed strategy。玩家不是固定选择一个行动,而是以某种概率分布在多个行动之间选择。比如 70% 概率合作,30% 概率背叛。
策略的选择受到 payoff 和 information 的影响
一个 agent 会根据自己知道的信息,去选择能最大化预期收益的策略。如果信息是完全的,所有玩家都知道彼此的策略空间和收益函数;如果信息是不完全的,某些玩家可能有私有信息,或者只能基于信念来判断其他人的状态
Nash Equilibrium
在一个策略组合中,如果其他玩家的策略不变,那么任何一个玩家都无法通过单方面改变自己的策略获得更好收益,这个状态就是纳什均衡
Taxonomy based on Game-Theoretic Elements
用“玩家—策略—收益—信息”四个维度,把 LLM 多智能体系统整理成一个博弈论框架
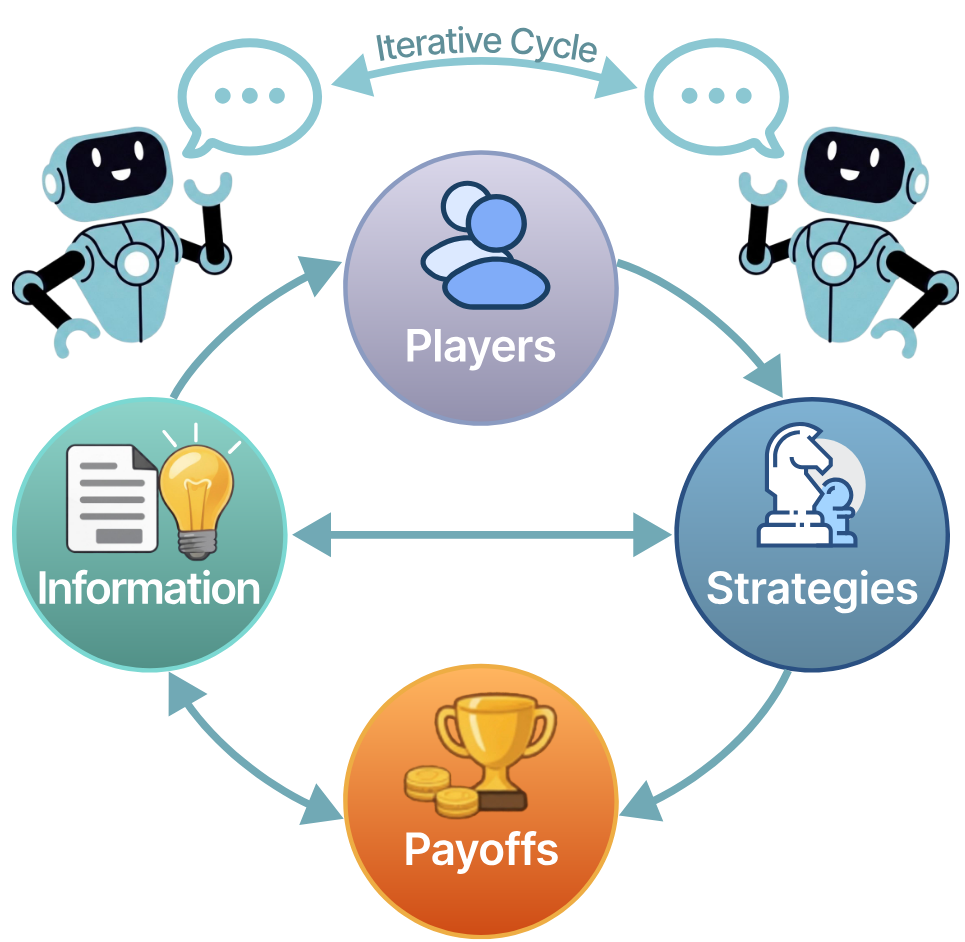
ProxyWar: Dynamic Assessment of LLM Code Generation in Game Arenas
把生成的代码放入游戏环境中,让他们动态对战、排名,评估代码的实际表现
Related work
Code Generation Quality Assessment
代码生成质量评估方法的三个阶段
1️⃣ BLEU。比较生成代码和参考答案在文本维度上是否相似(n-gram 重合度)。但是,代码不像自然语言,只看表面的相似度是不够的
2️⃣ CodeBLEU。在文本重合度的基础上,增加了代码关键词权重、抽象语法树 AST 相似度、数据流匹配这几个评估指标,尝试看代码的语法结构和数据流的关系。依赖参考答案,不能真正判断代码是否功能正确
3️⃣ Pass@k。模型生成 k 个候选代码,只要其中至少有一个通过测试用例,就算成功。从生成代码和参考答案的相似度,转向生成代码能否通过测试。但存在测试用例是否充分、是否泄露的问题
Limitations of Current Approaches
现有代码生成 benchmark 有明显的 simplicity bias,也就是“简单任务偏差”
1️⃣ Simplicity Bias and Limited Scope。当前 benchmark 任务太简单,范围太窄
2️⃣ Dataset Contamination and Memorization。模型 benchmark 分数高,不一定代表它真的会解决问题;它可能只是记住了训练数据里的类似题目
3️⃣ Static Evaluation Misses Dynamic Reality。传统 benchmark 通常只看代码能不能通过一组固定测试。但真实开发中,程序员会反复调试、根据编译错误和运行反馈修改代码,还要处理复杂交互场景。现有 benchmark 很少评估这种迭代修复能力和动态运行表现
4️⃣ Limited Quality Dimensions。现有指标几乎只关注 functional correctness,但忽略了很多实际很重要的维度,例如 Efficiency, Robustness, Maintainability, Creativity