LLM基础知识指北
简单梳理llm内容
一、LLM的不足
- llm的幻觉:答非所问
- 健忘:容易忘掉之前的交互内容
- 知识时效性有限:时效性截至最终训练时的知识库
- 功能有限:仅仅具备文字推理功能
二、RAG
RAG(检索增强生成,Retrieval Augmented Generation),先从外部知识库中检索相关数据,再结合LLM生成更精准且上下文相关的内容。
RAG的核心在于将传统的信息检索技术与语言生成模型相结合。
原始RAG方法
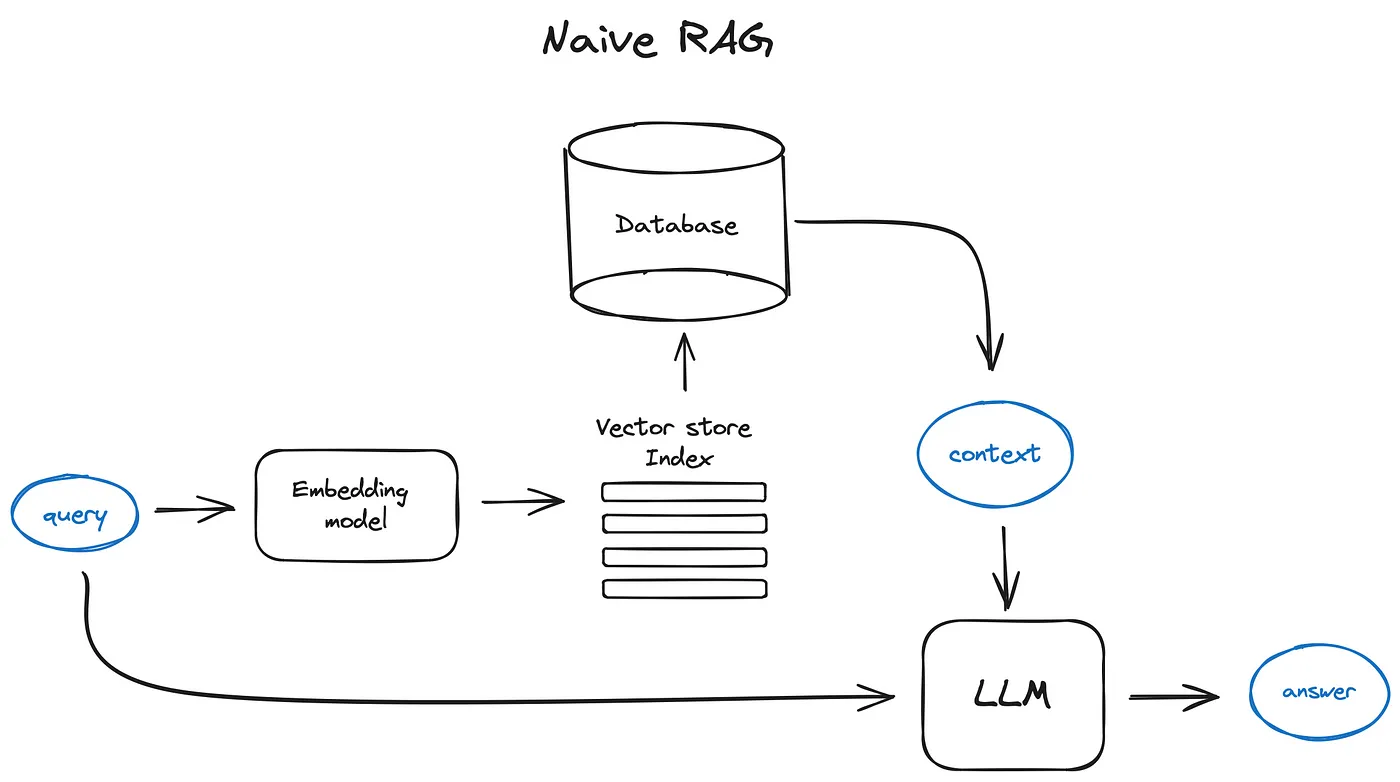
将文本分割成小块,然后将其转换为向量。
把这些向量汇总到一个索引中,最后创建一个针对LLM的提示,直到模型根据在搜索中找到的上下文回答问题。
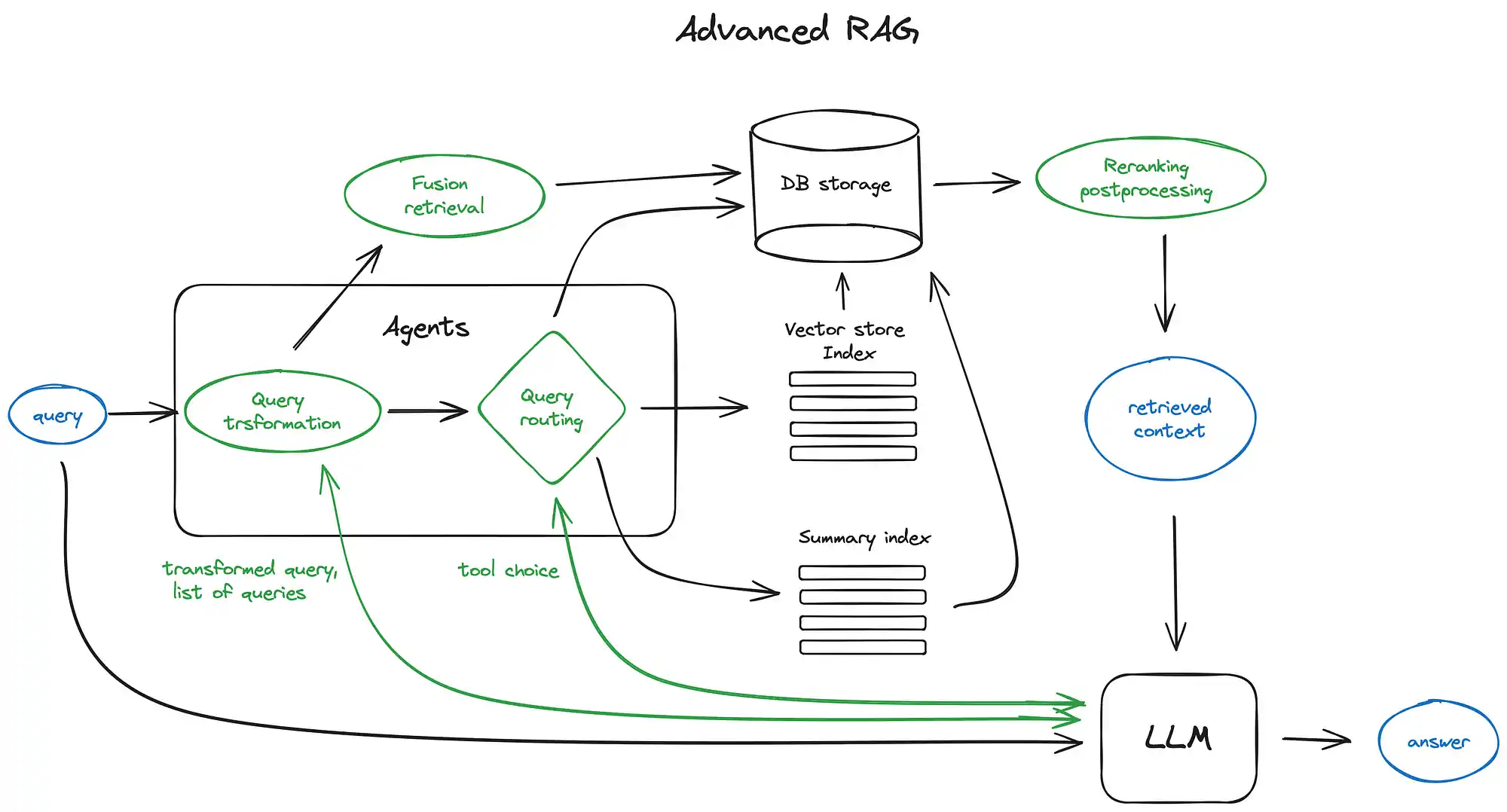
高级RAG方法
三、Agent
智能体是能够自主执行任务的系统,其本质是一种强化学习或规划算法与语言模型的集成,能够实现复杂的指令并动态适应环境变化。
广义(理想化)
Agent 是能够感知其所处环境并采取行动以实现特定目标或完成特定任务的自主实体。
它可以广泛应用于机器人、自动驾驶、对话系统、推荐系统、游戏 AI、分布式系统以及多智能体协作等各种场景。
是实现 AGI(通用人工智能)的最佳途径。
狭义
可以通过工具应用扩充功能的,多模态的 AIGC 应用
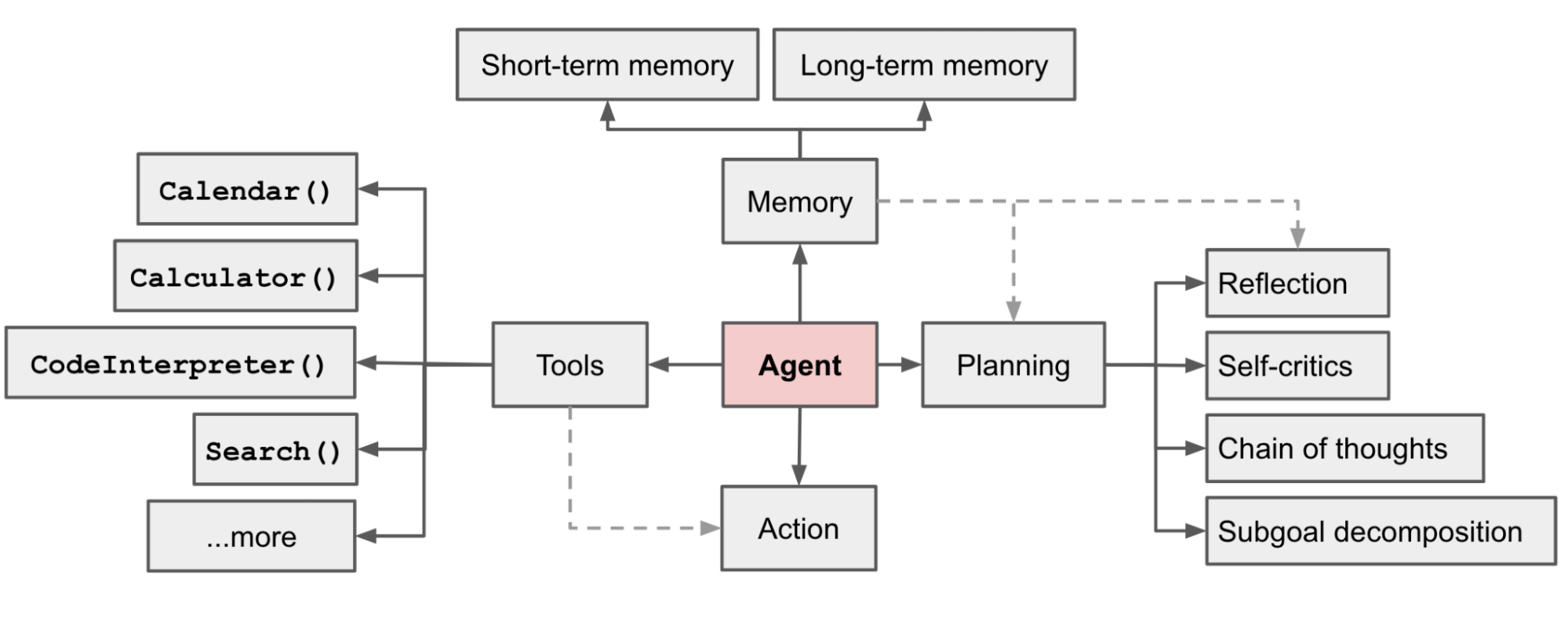
agent的几个关键组件
Planning
- 将大型任务分解为更小、更易于管理的子目标,从而能够高效地处理复杂任务
- 对过去的行为进行自我批评和反思,提高最终结果的质量
Memory
短期记忆
上下文的学习就是在利用模型的短期记忆进行学习
长期记忆
通常是利用外部向量存储和快速检索实现,赋予智能体在较长时间内保存和调用(无限)信息的能力
Tools
调用api接口,以获取模型权重中缺失的额外信息(预训练结束后这些信息很难更改,这些信息包括时事信息、代码执行能力、对专有信息源的访问权限等)
Planning
任务分解
- CoT(Chain of thought):用于提升模型在处理复杂任务的表现。要求模型“逐步思考”,以便在测试阶段利用更多的计算资源,将困难的任务分解为更小、更简单的步骤。
- ToT(Tree of thought):将问题分解为多个思维步骤,并且在每个步骤中生成多种思路,从而成为一个树状结构。搜索过程使用广度优先(BFS)或者深度优先(DFS),并且通过分类器(借助提示)或多数表决的方式对每个状态进行评估。
任务分解的方法
- 在prompt中写入简单的提示,比如“完成123步骤”
- 使用特定的指令,比如说先写一个大纲
- 借助人类输入
- LLM+P,依赖外部的经典规划期进行长期规划。使用规划领域定义语言(PDDL)作为中间接口秒偶数规划问题。
自我反思
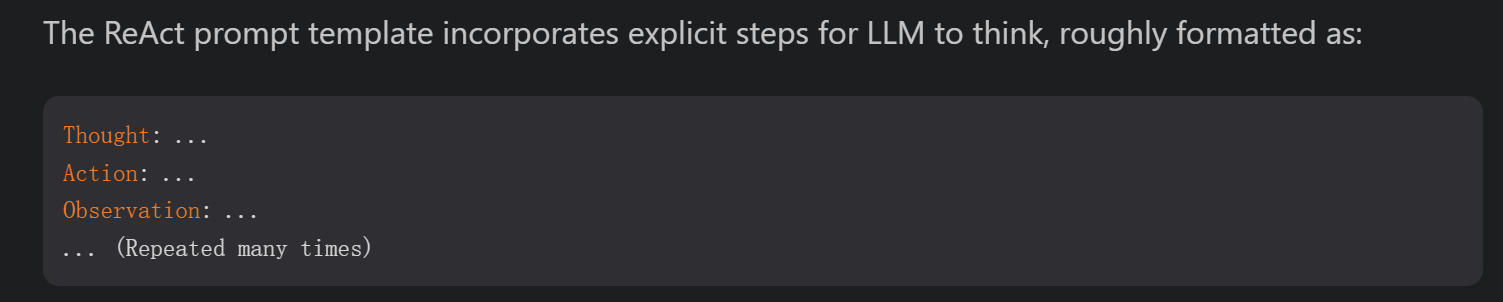
ReAct:将行动空间扩展为特定任务的离散行动与语言空间的组合,在LLM中集成了推理(使得LLM能够与环境进行交互,例如使用搜索引擎搜索API接口)和行动(LLM用自然语言生成推理的过程)功能。
ReAct模板中让LLM进行思考的步骤:
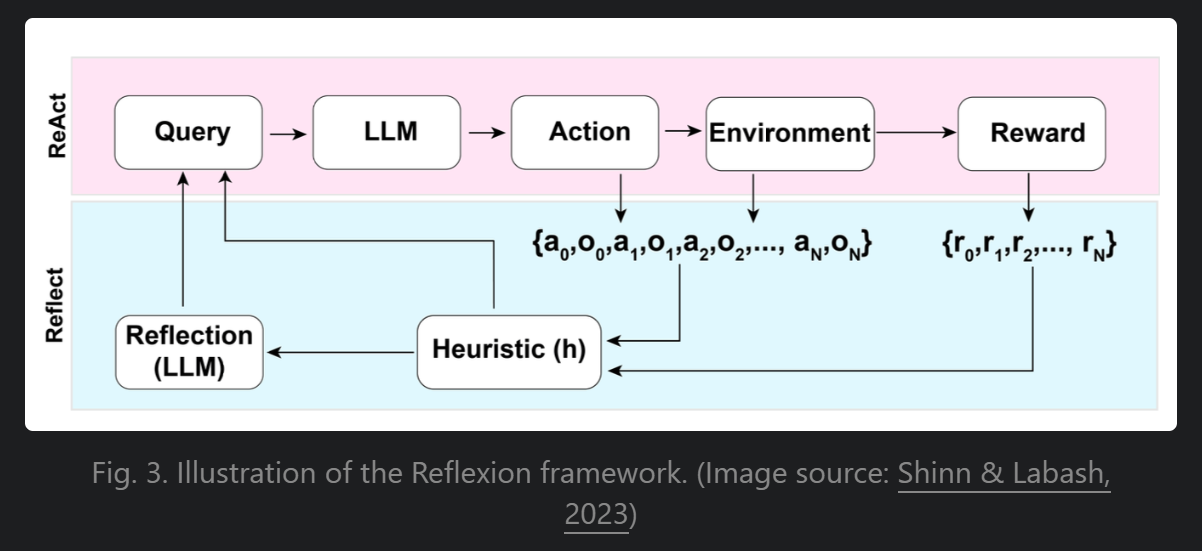
Reflexion:赋予agent动态记忆和自我反思能力。采用标准强化学习设置,其中奖励模型提供简单的二元奖励,行动空间遵循ReAct的设置,即特定任务的行动空间通过语言进行扩展。
CoH(Chain of Hindsight):通过向模型明确展示一系列过往输出,并为每个输出标注反馈信息,以促使模型对自身的输出进行改进。核心思想是在上下文中展示逐步改进的输出历史,并训练模型顺应这种趋势,从而产生更好的输出。
Tips:个人理解,CoH 主要用于模型微调阶段,CoT 和 ToT 主要应用于任务处理过程中的提示词
Memory
人脑记忆的分类
感觉记忆(Sensory Memory)
记忆的最初阶段,在原始刺激结束后,保留对感觉信息(视觉、听觉、触觉等)的印象,最多持续几秒
短期记忆(Short-Term Memory)/ 工作记忆(Working Memory)
存储当下意识到的执行学习、推理等复杂认知任务所需的信息
长期记忆(Long-Term Memory)
存储很长时间,且容量基本无限

人脑记忆与LLM之间类似的映射关系
- 感觉记忆 - 对原始输入(文本、图像或其他模态)的学习嵌入表示
- 短期记忆 - 上下文学习,是短暂且有限的(受上下文窗口长度的限制)
- 长期记忆 - 外部向量存储库
Tools
四、 Workfslow
AI Workflow = Workflow + AI Node(Agent 等)
由人来规划个步骤具体流程,实际的Agent 也可以在流程中充当一个节点,最终来准确实现既定任务。
参考
[白熊游戏-LLM工具的基础知识]: https://gitee.com/chutianshu1981/AwesomeUnityTutorial/blob/main/AI%E9%A9%B1%E5%8A%A8%E6%B8%B8%E6%88%8F%E5%88%9B%E4%BD%9C101/ep02-LLM%20%E5%B7%A5%E5%85%B7%E7%9A%84%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86.md “白熊游戏-LLM工具的基础知识”
[高级 RAG 技术:图解概览]: https://baoyu.io/translations/rag/advanced-rag-techniques-an-illustrated-overview “高级 RAG 技术:图解概览”
[WengLilian-LLM Powered Autonomous Agents]: https://lilianweng.github.io/posts/2023-06-23-agent/ “WengLilian-LLM Powered Autonomous Agents”